Cover Image
1 / 1
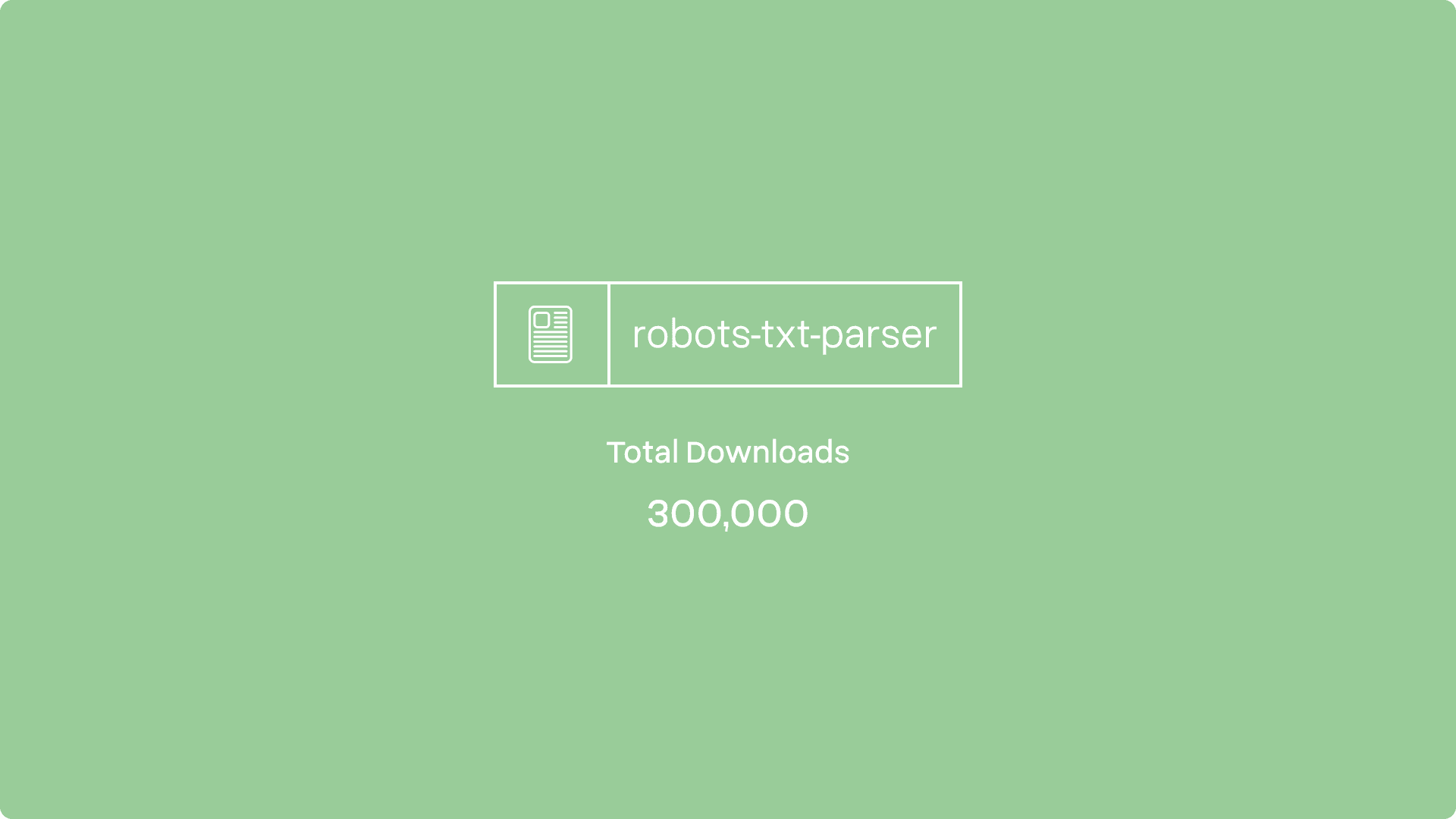
An open-source robots.txt parser designed for use in web scraping or crawling projects running on Node.js. Originally developed from a hobby project, I've improved and built upon it over the years, introducing TypeScript typings, additional features, as well as bug fixes, and general maintenance. With three revisions, weekly downloads anywhere between 1000 - 2000, and over 300,000 lifetime downloads, it has proven to be a successful project that filled a niche.
What I Did
- Fully developed a robots.txt parsing library in JavaScript solo as well as built out a full suite of tests.- Provided 4+ years of support, answering queries and fixing bugs whereever they occur.
- Starting work on built-in typescript types to future-proof the library as well as expand out to a new audience.